The 4acCPred framework
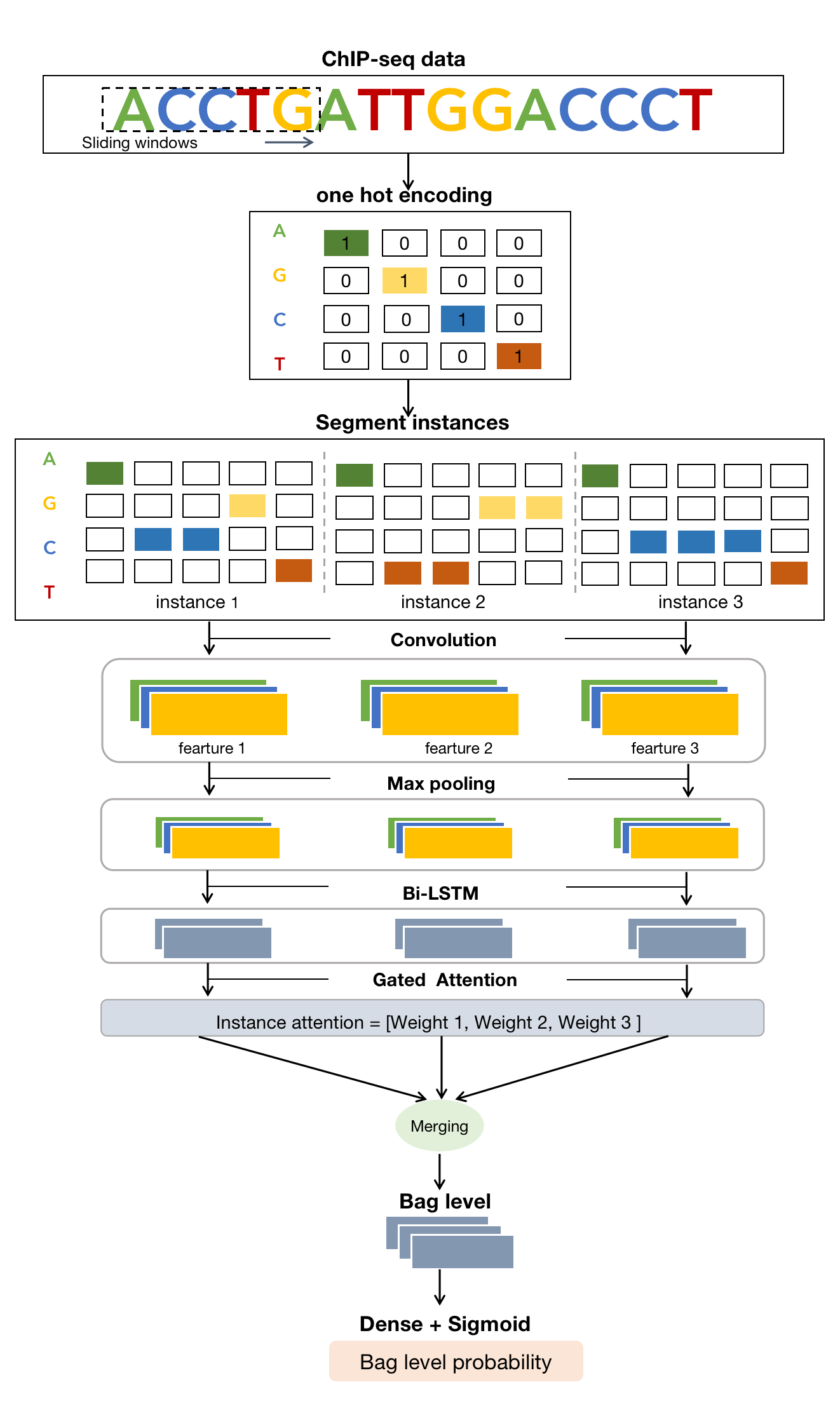
The 4acCPred framework treats each DNA sequence as a "bag" with multiple subsequences known as "instances". The underlying logic of the multiple instance learning framework used in 4acCPred is that the network should highlight instances in positive data that contain target methylation and capture their sequential patterns. Conversely, for negative data, the model should treat all instances as negative.
The network structure used to extract sequence features consists of one convolutional layer and one bidirectional long short-term memory (LSTM) layer. One of the greatest strengths of CNNs in genomics is that it naturally captures sequence motifs for a given target through its local receptive fields. However, it inevitably overlooks hidden long-term dependencies between sequential patterns, which can be addressed by using LSTMs. Between CNN and LSTM, we add a max-pooling layer to filter weak features and expand the receptive field; and a dropout layer to prevent overfitting in model training. It is worth noting that the network uses shared weights to extract features for each instance.
A key step of MIL framework is to merge the instance-level features to obtain the bag-level probability (i.e., the predicted value that a DNA sequence contains at least one 4acC methylation). It firstly lets the network output a score for each instance and then uses functions such as mean, max, and Noisy-and to aggregate the scores into one value for the entire bag. We assign weights to each instance using an attention mechanism and treat the weighted sum of all instance features as the final bag representation. Specifically, we use gated attention, which consists of three fully connected layers.