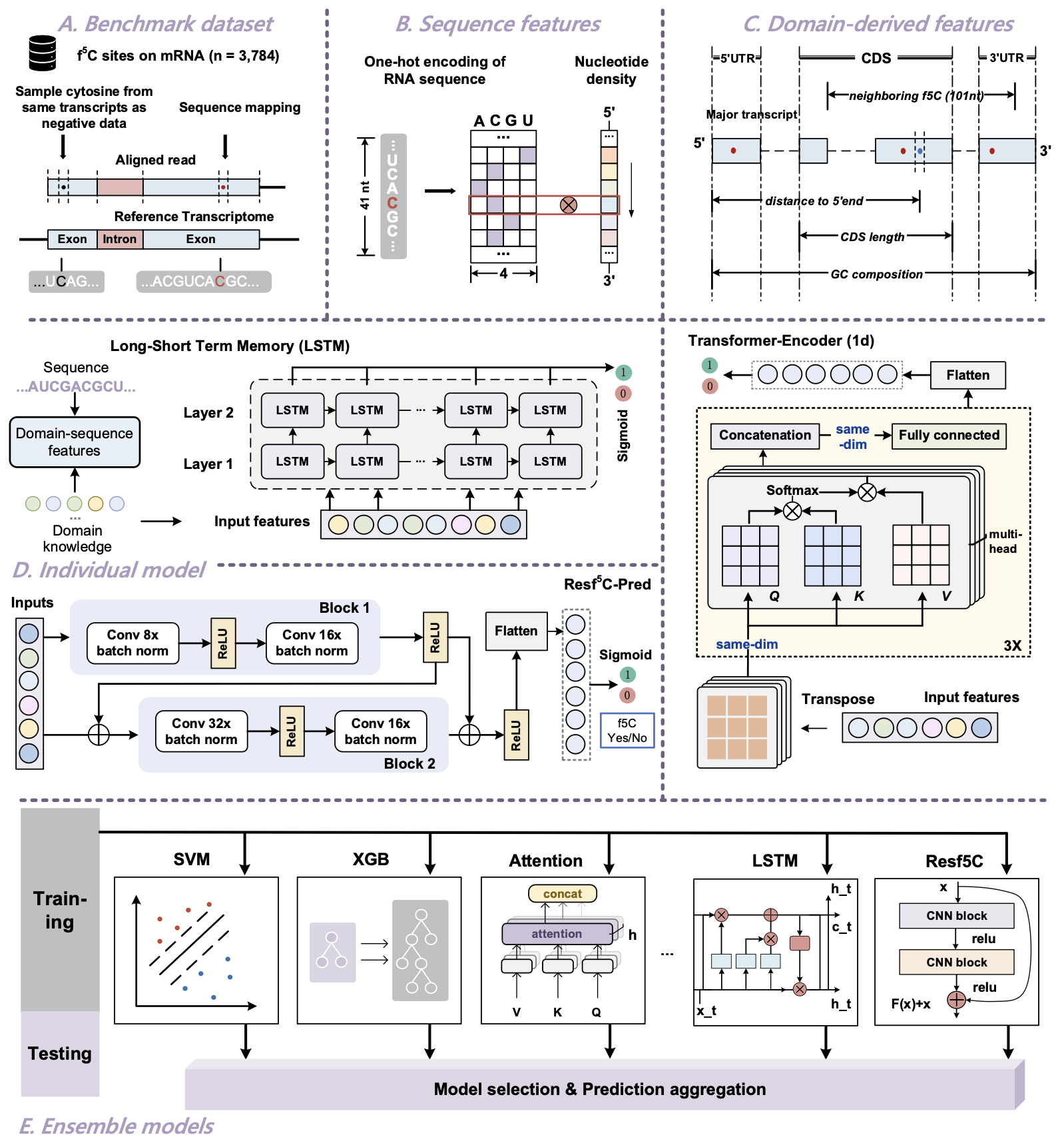
Resf5C-Pred (D section in the Figure under "Model" page) is a deep learning model used for two categories classification. It is trained on both sequence features and genomic features, outperforming other sequence-domain integrated methods such as CNN, LSTM and Transformer Encoder. For sequence features, one-hot encoding (OH) and nucleotide density (ND) is applied; for genomic features, 32 additional genome-derived features is applied. For model architecture, it consists of two convolutional blocks, subsequent dense layers, and an output layer with two neurons to predict whether a site is f5C modified or not. To be specific, two convolutional blocks are both 1-dimensional with a kernel size of 3, stride of 1, and padding of 1. Inside the first convolutional block, data first pass through a convolutional layer and then normalized according to batch, finally undergoing a ReLU activation. The processed data are then into another convolutional layer, followed by a dropout layer with a dropout ratio of 0.1 to prevent overfitting. The second convolutional block shares a similar architecture as the first convolutional block except a dropout layer replaces the batch norm layer. Before entering the ReLU activation followed by each convolutional block, residual learning is implemented through a shortcut connection that adds the input of the previous block to its output. Finally, the output undergone by these two convolutional blocks is flattened, passed through dense layers, and culminated in a sigmoid activation function for binary classification (f5C Yes/No).
Ensemble model (E section in the Figure under "Model" page) considered multiple combinations of methods to give a comprehensive evaluation. Sequence-domain integrated methods with high AUROC in cross validation set and independent test set were selected for constructing ensemble model. Therefore, since XGB (eXtreme Gradient Boosting Machine) and Resf5C are two top models, outperforming other sequence-domain integrated methods. They were selected for ensemble model construction. The ensemble method aggregates predictions from these two different models by taking an average of their output to make a final decision. Due to the combination of multiple models, the integrated model tends not to be overly dependent on specific features of the training data, thus reducing the risk of overfitting. The combination of multiple models can improve the accuracy of predictions and is less sensitive to small changes and outliers in the data.
Figure below demonstrated the overall workflow of developing Resf5C-Pred and ensemble models. It entailed the following steps: It entailed the following steps: (A) We collected f5C modification sites derived from f5C-seq and sampled cytosine from the same transcripts as negative data. (B) We extracted the RNA primary sequence of 41 nt containing cytosine in the middle, which is a potential f5C modification to be evaluated. Each nucleotide in sequences was encoded into a discrete vector consisting of a one-hot representation plus nucleotide density. (C) For each potential f5C modification, we generated 32 additional domain-derived features that may contribute to the prediction. A complete list of these genomic features can be found in Table S1. (D) The model architecture of individual LSTM, Resf5C-Pred, and Transformer-based method utilized for the computational identification of f5C. (E) The ensemble model was constructed by aggregating the predictions of selected machine learning and deep learning methods. For detailed model construction, such as transformer and ResNet, please visit my github repository: https://github.com/Jiaming21/F5C-codes.git