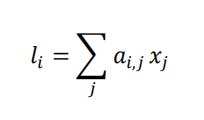The DPred Model
The DPred framework was mainly built upon the additive local self-attention and convolutional neural network. The attention layer uses additive attention to calculate the alignment weights indicating how much ‘attention’ it should give to each input state; A convolutional layer exploits key features in its local receptive fields; a max-pooling layer removes unimportant features and enlarges the receptive field; all processed features are then flattened and fed into a dropout layer to avoid overfitting in model training and to increase the generalization of the network on unknown sequences. A fully connected layer eventually takes all the previous results and leads to a softmax function, which predicts if the input sequence contains D sites or not with a 0.5 threshold. The rectified linear unit (ReLU) is used as an activation function throughout the framework except the first local attention layer and the last layer, which utilize the softmax function.
The attention layer used in this model is the additive local self-attention. In this model, let xi and xj denote the i-th and the j-th element in the sequence respectively. It should first calculate the alignment (attention) weights ai,j , which is derived by aligning the state i with the state j:
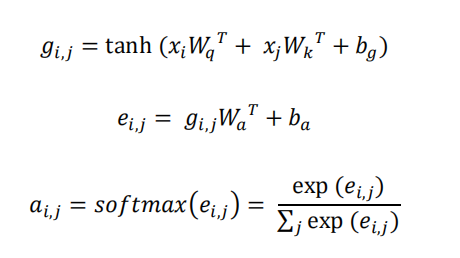
The ei,j is alignment score function. Here it used an additive structure, and that’s why we called this layer as an additive local self-attention. Besides this additive structure, the alignment score function can also take dot product, scaled dot product and cosine similarity operation. Furthermore, the local attention layer only focuses on a subset of context, that means for each state i, we should not calculate the alignment of every state in the sequence with it, but only part of them with it. We used monotonic alignment here, just setting the aligned position pi to be i, i.e., the i-th state is aligned with a window of states around itself. For example, If the window size is 5, each state in the sequence is compared to 2 states in front of it, to 2 states behind it and to itself respectively. Next, the alignment weights were obtained by feeding alignment scores through a softmax function. The weight indicates how much ‘attention’ it should give to each input state.
The states in the input layer were weighted to give a new vector that’s used by the next CNN layer. The new vector is this attention-focused state representation li, derived by the weighted average over the input sequence, which should have the same size with the input layer.